ai-berkshire 教程:把巴菲特、芒格、段永平、李录的方法论做成 Agent 工作流

很多 AI 投研项目的问题,不是答案写得不够像研报,而是太像研报了:结构完整,措辞稳重,最后你却不知道哪些数字查过,哪些假设只是模型顺嘴补上,哪些风险被漂亮地盖过去了。
xbtlin/ai-berkshire 有意思的地方在这里。它没有把自己包装成“AI 自动选股神器”,而是把价值投资研究拆成一套可执行的 Agent 工作流:四大师方法论、18 个 canonical skills、Claude Code 和 Codex 双入口、多 Agent 分工、金融严谨性工具、报告抽检准出。看完源码后,我更愿意把它理解成一个“投研操作系统雏形”,不是一个提示词合集。
先看可验证事实
本次调研基于仓库 README、skills/、codex-skills/、codex-prompts/、tools/、scripts/ 和 GitHub API。GitHub API 返回的信息是:仓库 xbtlin/ai-berkshire,MIT License,默认分支 main;截至本次查询,约 7.8k stars、990 forks,open issues 为 26。仓库描述写得很直白:AI 时代的伯克希尔,基于 Claude Code / Codex 的价值投资研究框架,四大师方法论加多 Agent 并行研究。
仓库规模也能说明它不是单文件玩具。本地浅克隆后,Git 跟踪文件超过 2200 个,其中报告 Markdown 很多;核心工作流集中在 18 个 skills/*.md,并同步到 Codex 侧的 skills 和 prompts。执行同步检查时,sync-codex-skills.py --check 和 sync-codex-prompts.py --check 均通过。
它真正解决的问题:把“投研习惯”变成可执行流程
价值投资方法论最容易被 AI 写成鸡汤:好公司、好价格、长期主义、护城河、管理层。每个词都对,但放进日常研究里经常没法执行。
ai-berkshire 的做法是把这些概念拆成 Agent 可以执行的步骤。比如 investment-research.md 不是让模型泛泛分析公司,而是要求按巴菲特、芒格、段永平、李录四个视角组织研究:商业模式是否简单可懂,护城河是否能被证伪,管理层是否值得托付,估值是否有安全边际,反方证据在哪里。
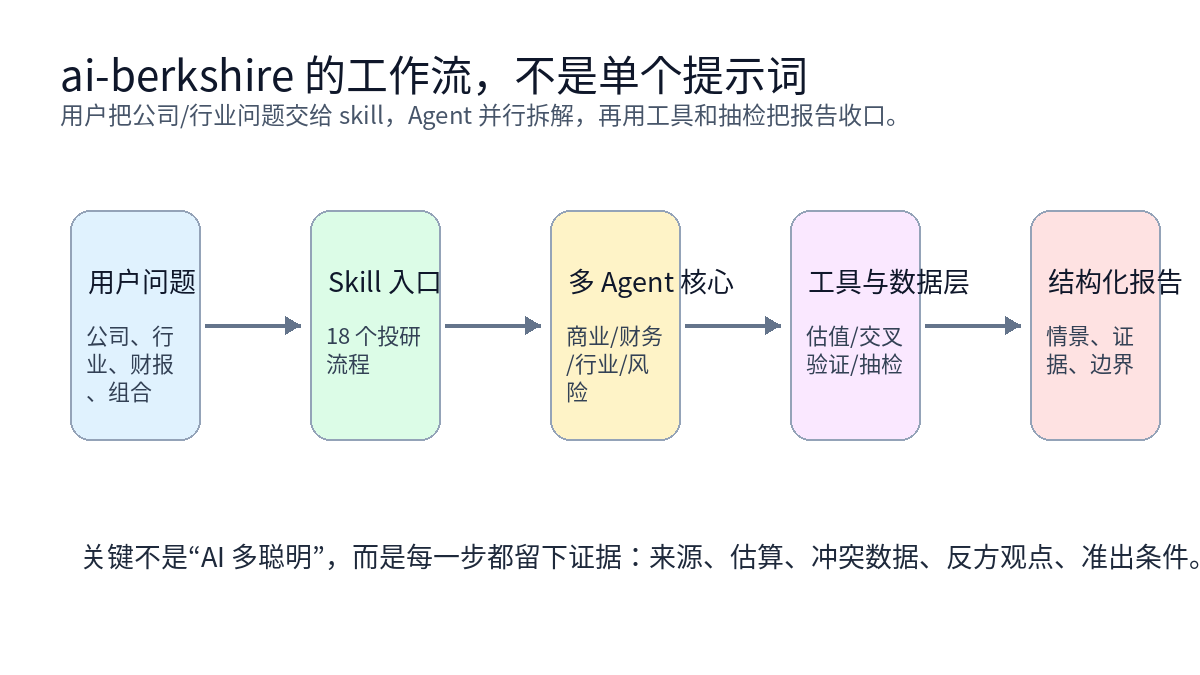
更关键的是,它显式要求 AI 承认“研究可得性偏差”。资料多的公司不等于确定性高,资料少的公司也不等于没价值。项目里会把研究对象按信息丰富度分级,提醒使用者:有些结论只是因为数据更容易拿到,而不是因为事实更强。
18 个 skills:投研不是一条命令
这个仓库的核心不是某个神奇 prompt,而是 18 个 canonical skills。它们覆盖从筛选到深研、从财报到组合、从新闻归因到公众号成稿的不同阶段。
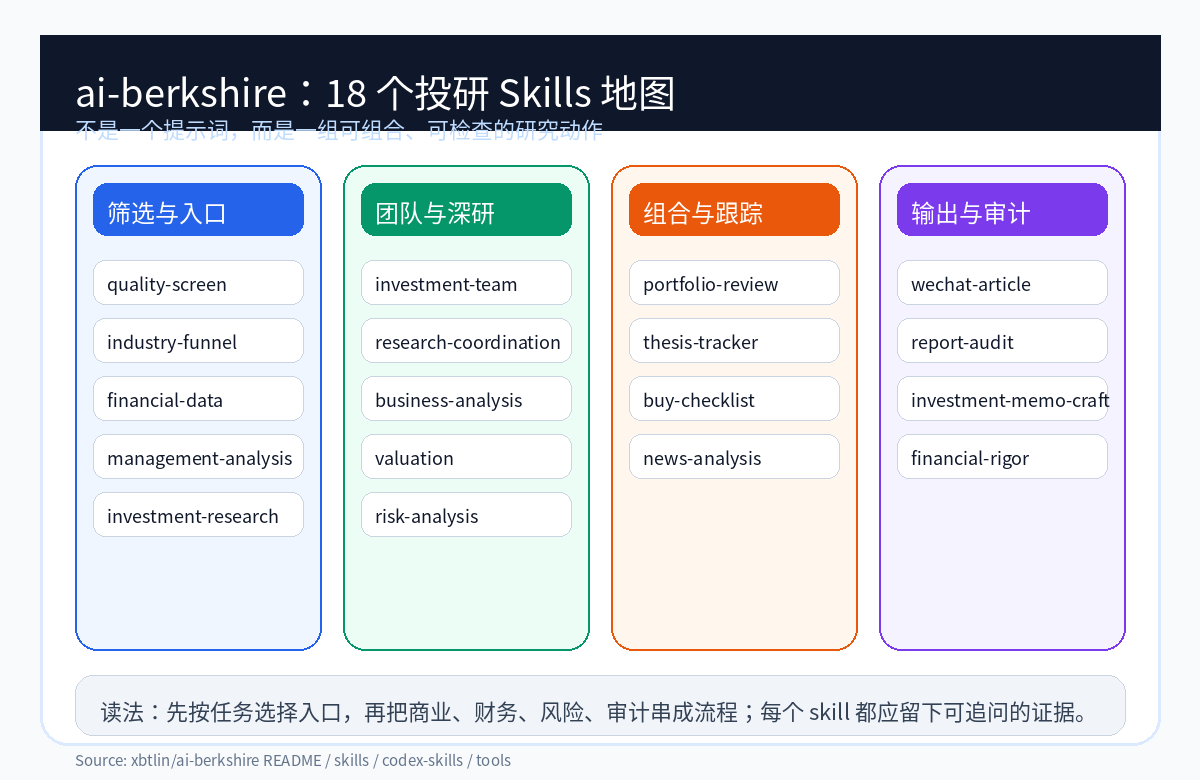
几个入口尤其值得看:
quality-screen用 7 条指标做去劣筛选,比如长期 ROE、自由现金流、利息覆盖倍数、OCF/NI、净利率、股本稀释等。它的目标不是找出牛股,而是先减少明显不适合深入研究的对象。investment-team把研究拆给多个角色:商业分析、财务估值、行业研究、风险评估,再由 team lead 收口。这个设计比单 Agent 长篇输出更接近真实投研团队。financial-data和financial_rigor.py负责把数据校验拉回现实,包括市值验算、估值验算、多源交叉验证、Benford 检查、三情景估值。report_audit.py提供报告抽检流程:先从报告里提取数据点,再抽样核验,最后给出准出或打回结论。wechat-article很有意思,它把研究报告再交给作者、编辑、读者三个 Agent 协作,说明作者不只想“研究”,也想把研究变成可读内容。
这套结构的好处是边界清楚。你想看一家公司,走 investment-research;想让多个 Agent 并行,走 investment-team;想先扫行业,走 industry-funnel;想复盘持仓,走 portfolio-review;想追踪买入后的 thesis,走 thesis-tracker。
金融严谨性:别让 AI 用漂亮话糊弄数字
我最看重的是 tools/financial_rigor.py 和 tools/report_audit.py。很多 AI 投研工具止步于“生成报告”,但报告的危险恰恰在于它看起来完整。
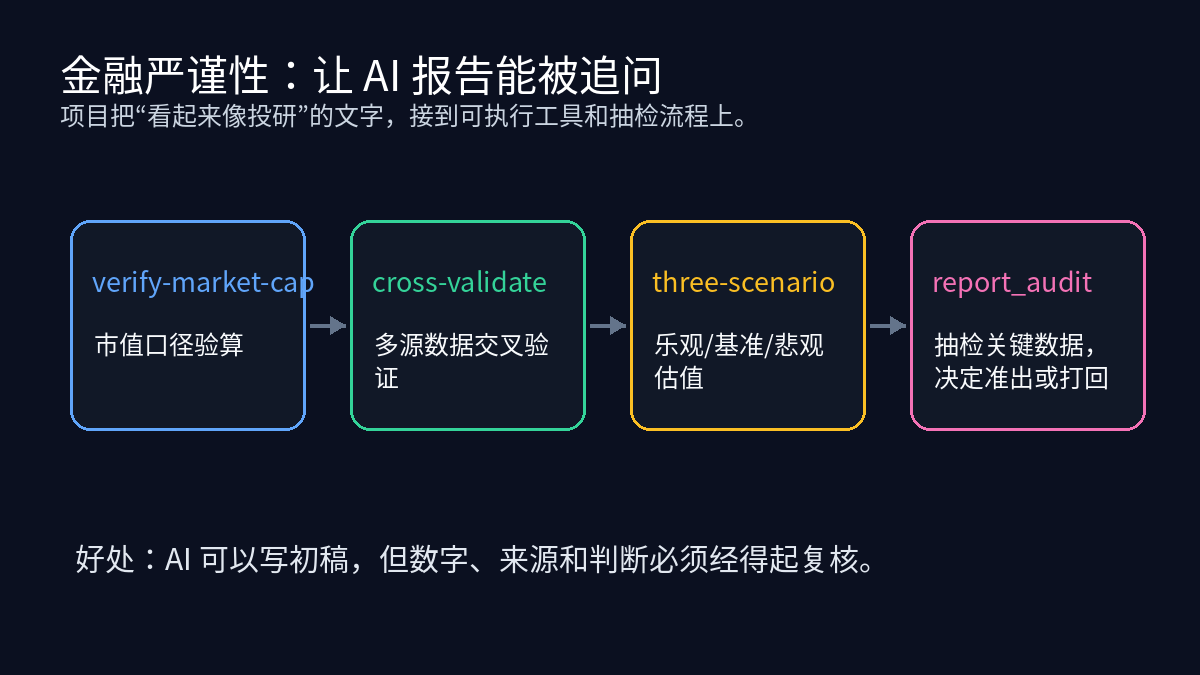
financial_rigor.py --help 里能看到几个实用子命令:verify-market-cap、verify-valuation、cross-validate、benford、calc、three-scenario。这些命令不保证你做出正确投资决策,但它们能把“请再严谨一点”变成具体动作:市值口径怎么算,估值假设是否一致,不同数据源有没有冲突,乐观/基准/悲观三种情景下结论是否变化。
report_audit.py 则是另一个关键补丁。它默认按比例抽检报告中的关键数据点,再根据核验结果决定准出或打回。这比让 Agent 自己说“我已经检查过了”可靠得多。真正的工作流应该允许报告被退回,而不是每次都顺利产出一篇漂亮 Markdown。
Claude Code 与 Codex:同一套方法论,两种入口
项目同时照顾 Claude Code 和 Codex。

Claude Code 的安装路径很直接:
git clone https://github.com/xbtlin/ai-berkshire.git
cd ai-berkshire
./scripts/install-claude-commands.sh
这个脚本会把 skills/*.md 复制到 ~/.claude/commands,并给工具脚本加执行权限。
Codex 侧则是:
git clone https://github.com/xbtlin/ai-berkshire.git
cd ai-berkshire
./scripts/install-codex-skills.sh
./scripts/install-codex-prompts.sh
sync-codex-skills.py 会从 canonical skills/*.md 生成 codex-skills/*/SKILL.md,避免两套内容长期漂移。仓库里还有一个 Codex-only 的 investment-memo-craft,它更像报告写作和排版 overlay,用来把研究输出整理成 decision-ready memo。要注意,它不替代数据校验,也不替代 report_audit.py。
一个最小使用方式
如果你只是想试试,不建议一上来就让它研究陌生小盘股。选一家你已经熟悉、资料充分、财报容易核验的公司更合适。
可以先这样问:
使用 investment-research 框架,研究 Costco。
要求:
1. 先给出 AI 研究可得性评级;
2. 分别用巴菲特、芒格、段永平、李录视角分析;
3. 列出至少 5 条反方证据;
4. 所有关键财务数据标注来源和年份;
5. 最后给出乐观、基准、悲观三种估值假设,不要给投资建议。
跑完之后,再把报告交给 financial_rigor.py 或 report_audit.py 的思路去核验。差的用法是“让 AI 告诉我买不买”;好的用法是“让 AI 生成一份可以被我逐项质疑的研究底稿”。这个差别很大。
适合谁,不适合谁
它适合三类人。
第一类是已经有投资框架的人。你不缺概念,缺的是把框架稳定执行下去的流程。ai-berkshire 能帮你减少漏项。
第二类是想学习价值投资研究流程的开发者。这个项目把抽象理念落成了 Markdown skills、同步脚本和工具脚本,适合当作 Agent workflow 工程样板看。
第三类是做内容或研究协作的人。wechat-article、investment-team、report_audit 这些设计,说明它不只关心模型输出,还关心输出如何被编辑、质疑和发布。
但它不适合想找“自动荐股答案”的人。项目不会替你承担投资结果,也不应该替你决定仓位。它也不能解决底层数据源质量问题;如果输入数据错了,Agent 只会更快地把错数据包装成完整报告。
我会怎么用它
我会把它放在“研究前半段”:搭框架、列问题、拆角色、收集反方证据、生成可审计报告。真正涉及买入、卖出、仓位和风险暴露时,还是要回到自己的资金约束、交易纪律和数据核验。
这个项目最值得借鉴的不是“巴菲特 + AI”的标题,而是一个更朴素的工程判断:让 Agent 写作很容易,让 Agent 留下可追溯的研究过程更难。ai-berkshire 正是在后者上花了力气。