avoid-ai-writing 源码拆解:把“去掉 AI 味”做成一套可审计的 Agent Skill
现在很多人说文章有“AI 味”。问题是,这句话通常没法执行。你让模型“写得像人一点”,它可能只是换几个词,删几个破折号,再把文章磨得更平,最后反而更像机器写的。
conorbronsdon/avoid-ai-writing 做的事更具体:它把“AI 味”拆成一组可审计的写作模式,再包装成一个可以放进 Claude Code、Hermes、OpenClaw、Cursor、Codex 等 Agent 工具里的 SKILL.md。它不是商业 AI 检测器,也不把结果当成判决;它更像一份写作质检清单,告诉 Agent 该看哪里、怎么改、什么时候只标记不改。
我看完 README、SKILL.md、detector/、Cursor 规则和插件脚本后,觉得这个项目最值得学的不是“列了多少禁词”,而是它把一个主观写作问题做成了工程化流程:规则有层级,输出有格式,检测器有测试,跨 Agent 分发也有同步脚本。
先看项目状态
几个可验证信息放在前面:
- 仓库:
conorbronsdon/avoid-ai-writing - GitHub 描述:用于审计和重写内容,移除 AI 写作模式,可配合 Claude Code、OpenClaw、Hermes 等 Agent 使用
- License:MIT
- 当前浅克隆提交:
6e1369d,提交信息是Detector: cover inflected forms of single-form verb patterns (#38) SKILL.mdfrontmatter 版本:3.10.0- GitHub API 查询:约
1.9k+stars、200+forks,默认分支main package.json里检测器要求 Node>=18,测试命令是node detector/patterns.test.js && node detector/categories.test.js- 我本地执行
npm test,检测器 fixtures 和CATEGORIES.md映射校验均通过
这里有一个容易误解的点:README 说它是 “Audit & rewrite content to remove AI writing patterns”,但 SKILL.md 第一段就把边界讲清楚了。它是写作质量工具,不是判定一个人是否使用 AI 的证据。规则会误伤非母语写作者、赶稿的人、技术文档和某些平台化写法,所以它更适合用来改稿,而不是审判作者。
它解决的不是“检测”,而是“可执行的改稿”
普通提示词通常长这样:
帮我把这篇文章去掉 AI 味,写得自然一点。
这句话的问题是没有验收标准。什么叫自然?哪些句子必须改?哪些只是风格选择?改完之后怎么确认没有把原意改坏?
avoid-ai-writing 的做法是把任务拆成三个模式。

rewrite是默认模式。Agent 要先列出命中的 AI 写作痕迹,再给出重写版本,然后说明改了什么,最后做一次 second-pass audit。detect只标记不改写。适合审稿、分析别人的文章,或者你不想让模型直接动原文的时候。edit面向文件。用户指向draft.md或 README,Agent 只做局部修改,保留已经自然的段落,并在最后报告改动和验证结果。
这个设计比一句“humanize”更可靠。因为它让 Agent 先解释问题,再动手改稿;如果你不同意某个判断,可以回到具体句子讨论,而不是和模型争论“有没有 AI 味”。
规则层级:先救命,再润色
SKILL.md 里不是把所有问题混在一起,而是给出了 P0、P1、P2 三层优先级。

P0 是可信度杀手,比如:
- “As of my last update” 这种模型截止声明;
- “Great question!”、“I hope this helps!” 这类聊天界面残留;
- “Experts believe” 但没有任何专家或研究来源;
- 把普通事件硬写成 “watershed moment” 或 “marking a pivotal moment”。
P1 是发布前应该修掉的明显 AI 味,比如 delve、leverage、robust 这类词表命中,模板句,let's explore 开头,过度同义词轮换,社交媒体里“this one is worth your time” 这种空推荐。
P2 更像风格润色:段落长度太整齐、结尾太泛、结构太像模板、偶发的 “serves as / features / boasts”。这些不一定毁稿,但会让文章看起来像流水线产物。
这个分层很实用。真实改稿时,不应该把所有规则当铁律。先清 P0,再处理 P1,最后看 P2 是否真的影响阅读。否则你会陷入另一种机器味:每个句子都“正确”,但没有人的呼吸。
它不是单纯禁词表
README 里提到 109-entry word replacement table across 3 tiers + 10 Tier 3 phrases,很容易让人以为这只是一个禁词清单。源码并不是这么简单。
SKILL.md 把规则分成几类:
- 词和短语:例如
delve、leverage、game-changer、the future looks bright; - 句式:例如 “It’s not X, it’s Y”、hedge-stacked predictions、rhetorical question openers;
- 结构:例如过多标题、裸名词短 bullet、段落长度过于均匀;
- 元数据泄漏:例如
[INSERT SOURCE]占位符、utm_source=chatgpt.com、contentReference[oaicite:0]; - 写作者自检:例如 paragraph-reshuffle immunity 和 treadmill effect。
最后两项特别值得拿出来讲。
paragraph-reshuffle immunity 的意思是:如果你把正文两段互换位置,文章几乎不受影响,那你写的可能不是论证,而是一串可替换的观点卡片。AI 文章常见这个问题,每段都像独立模块,彼此没有承接。
treadmill effect 更直接:每段读完问一句“这里新增了什么?”如果 40% 到 60% 内容删掉不影响信息,说明文章在原地跑步。很多 AI 稿不是错,而是不前进。
这两个规则没法靠正则稳定检测,却非常适合交给 Agent 做二次审稿。它们也是这个项目比普通检测器更像“写作编辑器”的地方。
detector 目录:把一部分规则变成可测试代码
仓库不只有 SKILL.md。detector/patterns.js 是一个零依赖检测引擎,README 里给了最小调用方式:
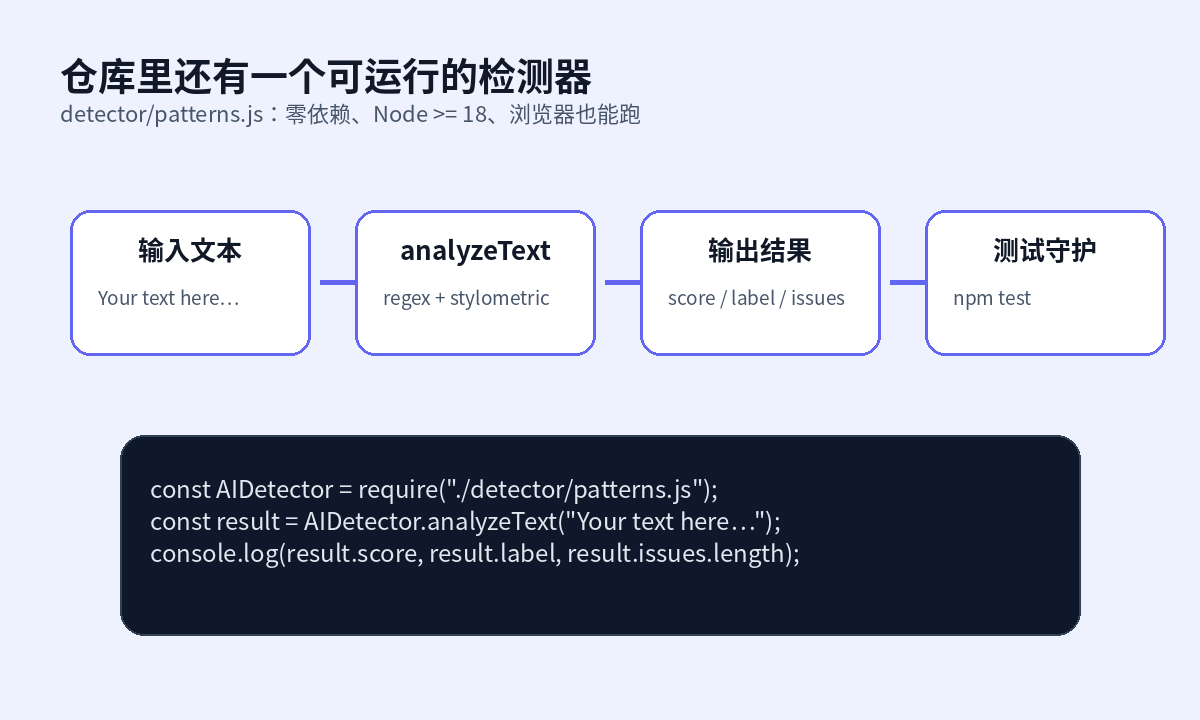
const AIDetector = require("./detector/patterns.js");
const result = AIDetector.analyzeText("Your text here…");
console.log(result.score, result.label, result.issues.length);
detector/README.md 说明了返回结构:score 是 0 到 100,label 有 Minimal、Some、Strong、Heavy,issues[] 记录每个命中的模式,stats 里有词数、上下文模式、归一化标记等信息。它还给出 document_classification、class_probabilities 和用于 UI 高亮的 highlight_sentence_for_ai。
这里的工程判断很克制:检测器是 false-negative biased。也就是说,它宁愿漏掉一些 AI 痕迹,也不轻易把可疑文本判成 AI_ONLY。detector/CATEGORIES.md 还专门解释:SKILL.md 的人类可读规则、检测器里的 44 个 type、README 里的 pattern-category count 不需要强行相等。因为有些规则是语义判断,不适合写成正则。
我本地跑了一次:
npm test
结果显示 patterns.test.js 的 fixtures 全部通过,categories.test.js 也确认 44 个 detector types 都在 CATEGORIES.md 里有映射。这种 anti-drift 设计很关键。写作规则最怕越改越散,最后 README、技能文件、检测器各说各话。这个仓库用测试把漂移控制住了。
最小上手路径
如果你只想试用,不需要先理解全部规则。

Hermes 可以直接把 SKILL.md 放进技能目录:
mkdir -p ~/.hermes/skills/writing/avoid-ai-writing
curl -o ~/.hermes/skills/writing/avoid-ai-writing/SKILL.md https://raw.githubusercontent.com/conorbronsdon/avoid-ai-writing/main/SKILL.md
Claude Code 可以 clone 到 skills 目录:
git clone https://github.com/conorbronsdon/avoid-ai-writing ~/.claude/skills/avoid-ai-writing
Cursor 走 .cursor/rules/:
mkdir -p .cursor/rules
curl -o .cursor/rules/avoid-ai-writing.mdc https://raw.githubusercontent.com/conorbronsdon/avoid-ai-writing/main/cursor-rules/avoid-ai-writing.mdc
触发方式不用复杂命令,直接对 Agent 说:
Audit this draft for AI tells.
Remove AI-isms from this post.
Run avoid-ai-writing in detect mode.
Edit draft.md in place and keep already-human paragraphs unchanged.
我的建议是:第一次不要直接用 rewrite。先用 detect 看它会标什么,再决定哪些规则适合你的文章。尤其是中文内容、技术文档、二语写作和品牌稿,不同场景容忍度不同。
一个推荐工作流
如果把它放进日常内容生产,我会这样用:
- 写第一版时不要开规则。先把观点、证据、例子写出来。
- 初稿完成后跑
detect。只看 P0 和 P1,别一上来修所有 P2。 - 对 P0 直接删除或补证据。比如 “专家认为” 要么写明来源,要么删掉。
- 对 P1 做局部改写。尤其是模板句、空洞结尾、
let's过渡、过度同义词轮换。 - 最后再跑一次
rewrite或edit,但要求 Agent 保留具体事实、命令、数字和个人判断。
坏做法是:
把整篇文章改得不像 AI,越自然越好。
好做法是:
Run avoid-ai-writing in detect mode. Focus on P0/P1 only. Keep technical terms, code blocks, quoted examples and source facts unchanged. For each rewrite, explain the exact sentence you changed.
后者会明显减少误伤。因为你给了模型边界:不是把文章重写成另一个人,而是把可疑痕迹清掉。
适合谁,不适合谁
它很适合四类人:
- 经常写英文技术博客、项目 README、LinkedIn/X 帖子的开发者;
- 用 Claude Code、Hermes、Cursor 做内容生产的人;
- 团队里需要审稿,但不想靠“感觉”争论 AI 味的人;
- 想把写作质量规则产品化、测试化的 Agent Skill 作者。
它不适合三种场景:
- 用来判定某个人“是不是用了 AI”。项目自己也明确说这只是 signal,不是 proof;
- 直接套到中文写作上当完整检测器。很多英文词表对中文没意义,但结构规则仍然有参考价值;
- 追求强营销文案的场景。它会天然压低夸张表达,如果你的平台就是靠夸张钩子吃饭,需要调整容忍度。
我最想借鉴的部分
这个项目给 Agent Skill 作者的启发很明确:不要只写一堆“你应该”。要把规则做成可维护系统。
avoid-ai-writing 至少做了五件对的事:
- 单一事实源:根
SKILL.md是核心,插件副本由脚本同步; - 版本化:frontmatter 有
version: 3.10.0,CHANGELOG 记录每次新增规则; - 跨平台:同一套规则适配 Claude Code、Cowork 插件、OpenClaw、Hermes、Cursor、Codex;
- anti-drift:
check-pattern-count.sh和categories.test.js防止文档、规则、检测器漂移; - 明确边界:反复强调“写作质量信号,不是判决”。
这比“我总结了 50 个 AI 味词汇”有用得多。词表会过时,模型会绕开常见禁词。但如果你抓的是结构、节奏、证据、输出格式和维护流程,这套方法就能继续迭代。
最后一句判断:如果你已经在用 Agent 写文章,avoid-ai-writing 不应该放在创作开始,而应该放在发布前。它不是帮你想观点的工具,而是帮你发现那些“读者一眼觉得像 AI”的痕迹。观点还是要自己有,证据还是要自己查。工具只能把机器味擦掉,不能替你长出判断力。