我拆了一遍 video-use:AI 剪视频真正难的不是看画面,而是读懂时间线
我拆了一遍 video-use:AI 剪视频真正难的不是看画面,而是读懂时间线
仓库地址:
https://github.com/browser-use/video-use.git
这篇不是把 README 翻译一遍,而是按真实仓库结构、本机命令、helper 脚本和工作流约束,拆一下video-use为什么把“AI 剪视频”做成了一个更像工程流水线的 agent skill。

很多“AI 剪视频”产品都喜欢讲同一个故事:把素材丢进去,模型看懂画面,然后自动给你剪出大片。
听起来很顺。
问题是,视频对模型来说太重了。
一分钟 30fps 的素材就是 1800 帧;十几条 take 叠起来,直接把画面逐帧交给模型,成本高、噪声大、也很难复现。更麻烦的是,剪辑真正要判断的东西往往不是“这一帧里有什么”,而是:哪句话表达最顺,哪个停顿该切,哪个 false start 要删,字幕和 overlay 是否压住了主体,切点有没有爆音。
browser-use/video-use 的选择很克制:它不让 LLM 直接看完整视频,而是先把视频变成可推理的时间线。
原始视频 → 词级转写 → takes_packed.md → LLM 决策 → EDL → ffmpeg 渲染 → timeline_view 自检
这套思路有点像 browser-use 本体:浏览器 agent 不应该只看网页截图,而应该读结构化 DOM;视频 agent 也不应该沉迷帧海,而应该读结构化时间线。
01 这个项目真正解决的不是“剪”,而是“让剪辑决策可控”
README 对它的定位很直接:把原始素材放到一个文件夹里,和 Claude Code、Codex、Hermes、Openclaw 这类有 shell 能力的 agent 对话,最后得到 edit/final.mp4。
它能做的事情包括:
- 删掉
umm、uh、false starts 和 take 之间的死空白。 - 给每个片段做自动调色,或者接入自定义 ffmpeg filter chain。
- 在每个切点加 30ms audio fade,避免硬切爆音。
- 按风格烧录字幕,默认是两词一组的大写字幕。
- 通过 HyperFrames、Remotion、Manim 或 PIL 生成动画叠层。
- 在展示给用户前,对渲染结果做 self-eval。
- 把项目记忆写到
edit/project.md,下次继续时能接上。
但如果只看这张功能清单,会低估它。
video-use 更重要的价值,是把视频剪辑拆成一套 agent 能执行、用户能审查、脚本能复现的协议。LLM 不直接碰素材,不直接拼最终命令,而是先读证据、写策略、等确认,再生成 EDL,最后交给 helper 和 ffmpeg 执行。
这就把“帮我剪一下”这种模糊请求,变成了可以追踪的工程流程。
02 它让 LLM “读视频”,但读的是两层压缩视图
README 里最值得记住的一句话是:The LLM never watches the video. It reads it.
第一层是音频转写。
helpers/transcribe.py 会先用 ffmpeg 抽取 mono 16kHz 音频,再调用 ElevenLabs Scribe。源码里明确设置了这些参数:
model_id: scribe_v1
diarize: true
tag_audio_events: true
timestamps_granularity: word
这意味着它要的不是普通字幕,而是词级时间戳、说话人分离和音频事件。(laughter)、(applause)、(sigh) 这类事件也会进入后续判断。
第二层是压缩后的主阅读视图。
helpers/pack_transcripts.py 会把 Scribe 的 word list 按两个规则压成 phrase-level Markdown:
遇到 >= 0.5s 的沉默就断句
遇到 speaker change 就断句
输出是 <edit>/takes_packed.md。README 示例长这样:
## C0103 (duration: 43.0s, 8 phrases)
[002.52-005.36] S0 Ninety percent of what a web agent does is completely wasted.
[006.08-006.74] S0 We fixed this.
这个文件才是 LLM 的主视图。它比原始 Scribe JSON 小得多,但保留了剪辑最需要的东西:时间范围、说话人、句子、停顿和可对齐的词边界。
视觉不是没有,而是按需出现。
helpers/timeline_view.py 会为某个时间段生成一张组合 PNG:上面是 filmstrip,下面是 waveform,再叠加 word labels 和 silence shading。它不是让模型从头看完整视频,而是在“这个 cut 是否稳”“这个停顿是不是该删”“这段画面有没有跳”这种决策点上,给一个局部证据。

这就是它的第一个关键判断:主视图用文本,疑难点才看图。
03 本机实测:先验证工具链,不擅自烧转写额度
我在本机做了低成本验证:
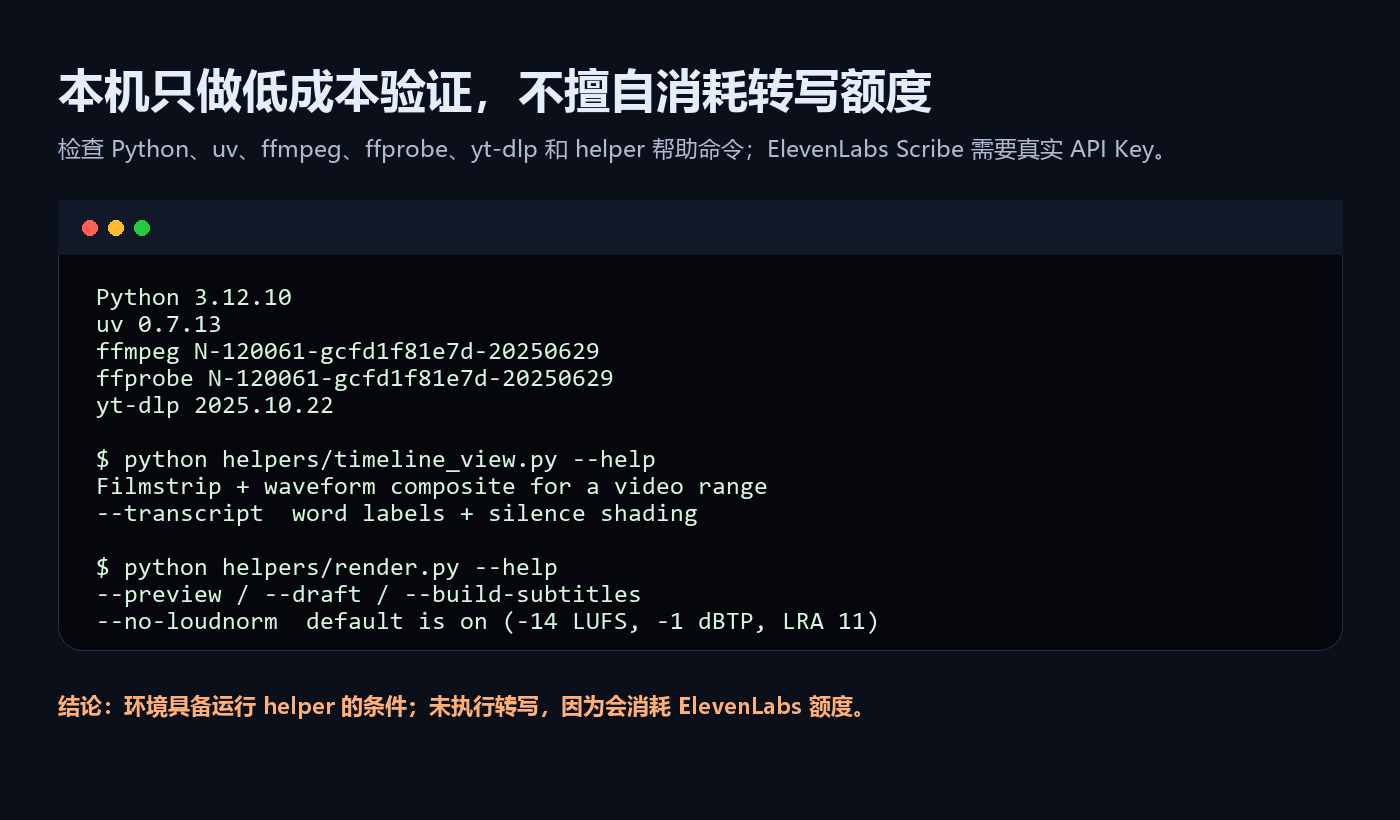
当前环境可用:
Python 3.12.10
uv 0.7.13
ffmpeg N-120061
ffprobe N-120061
yt-dlp 2025.10.22
并且 timeline_view.py、render.py 的 help 能正常读取。
这里有个实际使用时很容易踩坑的点:不要把“安装验证”做成“立刻转写一段视频”。
video-use 使用 ElevenLabs Scribe,真实转写需要 ELEVENLABS_API_KEY,也会消耗额度。更合理的验证顺序是:先确认 Python 依赖、ffmpeg、ffprobe、helper 命令可用;等用户真的给素材,并确认要开始剪,再执行转写。
这不是保守,而是成本控制。
04 安装时最容易装错的地方:不能只复制 SKILL.md
手动安装大概是这样:
git clone https://github.com/browser-use/video-use ~/Developer/video-use
cd ~/Developer/video-use
uv sync
# 或者
pip install -e .
系统依赖:
brew install ffmpeg
brew install yt-dlp # 可选,用于下载在线素材
Debian/Ubuntu:
sudo apt-get update
sudo apt-get install -y ffmpeg
pip install yt-dlp
Python 依赖来自 pyproject.toml:
requests
librosa
matplotlib
pillow
numpy
注意,注册 skill 时应该 symlink 整个仓库目录,而不是只复制 SKILL.md。
原因很简单:SKILL.md 旁边的 helpers/ 才是执行层。仓库里有这些脚本:
helpers/transcribe.py
helpers/transcribe_batch.py
helpers/pack_transcripts.py
helpers/timeline_view.py
helpers/grade.py
helpers/render.py
Claude Code:
mkdir -p ~/.claude/skills
ln -sfn ~/Developer/video-use ~/.claude/skills/video-use
Codex:
mkdir -p "${CODEX_HOME:-$HOME/.codex}/skills"
ln -sfn ~/Developer/video-use "${CODEX_HOME:-$HOME/.codex}/skills/video-use"
ElevenLabs key 放到 repo 根目录 .env:
cp .env.example .env
# 写入:ELEVENLABS_API_KEY=...
chmod 600 .env
可以用一个不做转写的接口先检查 key:
curl -s -o /dev/null -w '%{http_code}
' -H "xi-api-key: $(sed -n 's/^ELEVENLABS_API_KEY=//p' ~/Developer/video-use/.env)" https://api.elevenlabs.io/v1/user
返回 200 说明 key 可用,401 就是 key 错或过期。
05 日常使用:先盘点和确认,不要上来就剪
真正使用时,进入素材目录,而不是进入 video-use 仓库目录:
cd /path/to/your/videos
claude # 或 codex / hermes / openclaw
第一句最好不是“直接剪完”。我会这样说:
inventory these takes and propose a strategy. do not render yet.
这符合 SKILL.md 里的硬规则:strategy confirmation before execution。Agent 应该先盘点素材、读转写、给出剪辑策略,让用户确认后再动手。
确认后再说:
approved. produce a 60-90s launch video for X/TikTok, keep the strongest hook, burn subtitles, and render a preview first.
输出目录固定在素材目录下:
<videos_dir>/edit/
project.md
takes_packed.md
edl.json
transcripts/<name>.json
animations/slot_<id>/
clips_graded/
master.srt
preview.mp4
final.mp4
这个目录设计也很重要:源素材保持不动,所有中间产物和最终文件都进 edit/。这样你可以回查,也可以删掉重来。
06 render.py 的细节说明它不是玩具脚本
如果只看 README,会觉得这是一个 agent prompt 项目。但看 helpers/render.py,能看到很多视频工程里的脏活。
它的渲染路径大致是:
1. 每个 EDL range 单独 extract,带调色和 30ms audio fade
2. 用 -c copy 做 lossless concat,得到 base.mp4
3. 如果有 overlay 或字幕,再用 filter_complex 合成
4. 字幕最后应用
源码开头就写得很明确:
Per-segment extract with color grade + 30ms audio fades
Lossless -c copy concat into base.mp4
subtitles filter LAST
这几个点都不是装饰。
30ms audio fade 是为了避免硬切时的 pop 声;-c copy concat 是为了避免有 overlay 时反复二次编码;字幕最后应用是为了避免 overlay 把字幕盖掉;setpts=PTS-STARTPTS+T/TB 是为了让 overlay 的第 0 帧准确落到它在成片里的开始时间。
render.py 还提供了不同质量档位:
python helpers/render.py <edl.json> -o preview.mp4 --preview
python helpers/render.py <edl.json> -o draft.mp4 --draft
python helpers/render.py <edl.json> -o final.mp4 --build-subtitles
python helpers/render.py <edl.json> -o final.mp4 --no-subtitles
--draft 是 720p、ultrafast、CRF 28,适合快速检查切点;--preview 是 1080p、CRF 22,适合质量检查;默认还会做 loudness normalization,目标类似 -14 LUFS, -1 dBTP, LRA 11。
这些细节决定了它不是“LLM 随手拼 ffmpeg 命令”,而是把容易出错的地方收敛到脚本里。
07 12 条硬规则里,最值得记住的是这几条
SKILL.md 里有 12 条 hard rules。我认为最关键的是:字幕最后应用;每个片段边界加 30ms audio fade;永远不要切在词中间;切点要留 30-300ms padding;缓存 transcript;多个 animation slot 要并行 sub-agent 生成;执行前必须确认策略;所有输出都进 <videos_dir>/edit/。
这些规则看起来细碎,但本质上是在给 AI 剪辑加护栏:审美可以自由,生产正确性不能自由发挥。
08 动画叠层:它不是给你模板,而是给你并行工作包
video-use 支持 HyperFrames、Remotion、Manim、PIL 做 overlay animation。它没有说“永远用某一个引擎”,而是建议按具体 animation slot 选工具。
更有意思的是,它要求多个动画用并行 sub-agent 处理:一个 slot 一个 agent,文件名独立,交付物明确。一个 animation brief 至少要讲清楚:目标、绝对输出路径、分辨率、fps、codec、duration、色板、字体、逐帧时间线、不要做什么、验收清单。
这说明它的定位不是模板剪辑器,而是把视频工程拆成 agent 可以并行执行的小任务。
09 一个安全的实战流程
如果我真的拿它剪一组产品 launch 素材,我会这样走:
cd ~/Developer/video-use
uv sync
python helpers/timeline_view.py --help
ffprobe -version | head -1
然后把素材放进干净目录:
my-launch-video/
C0101.MP4
C0102.MP4
C0103.MP4
进入素材目录启动 agent:
cd my-launch-video
claude
先要求盘点:
inventory these takes and propose a strategy. do not render yet.
确认策略后,再渲染 preview:
approved. produce a 60-90s launch video for X/TikTok, keep the strongest hook, burn subtitles, and render a preview first.
最后要求它回看切点:
review the preview around every cut boundary and tell me what you fixed before final render.
这比“一键剪完”慢一点,但更适合真实工作:你知道它为什么这么剪,也能在 final 之前介入。
10 它适合谁,不适合谁
适合:talking head、访谈、教程、产品 launch video;有大量 take,需要从转写里挑干净表达;想让 agent 帮你做剪辑决策,但希望先审策略;熟悉命令行,愿意接受 ffmpeg、EDL、helper 脚本工作流。
不适合:只想拖拽时间线的传统剪辑用户;不愿配置 ElevenLabs key,或者不想用云端转写;需要强交互 GUI、复杂多轨手动精修的项目;没有素材上下文,却期待它一键做出电影级审美。
它不是魔法按钮。它更像一个把“剪辑助理”工程化的 agent skill。
我的判断
video-use 最值得借鉴的地方,是它没有贪心地让模型看所有东西。
它承认视频太重,于是把主任务转成词级时间线;它承认 LLM 不适合直接执行复杂媒体命令,于是把渲染交给 helper;它承认 agent 会犯错,于是保留确认、缓存、自检和项目记忆。
这套设计比“多模态模型直接看视频然后剪”更现实,也更便宜。
如果你要做 AI 视频工具,我建议先学它三个判断:
不要把原始视频直接喂给模型
不要让模型直接拼最终命令
不要跳过确认和自检
真正可靠的 AI 剪辑系统,不是让模型看得更多,而是让模型看到刚好足够、结构足够清楚、执行足够可控。
video-use 的价值就在这里。
参考资料
https://github.com/browser-use/video-use.gitREADME.mdinstall.mdSKILL.mdhelpers/transcribe.pyhelpers/pack_transcripts.pyhelpers/timeline_view.pyhelpers/render.py